Agilebase platform blog: recent updates
-
Refactoring SQL views
Here’s a blog post to act as a question for the PostgreSQL community. I’d love to know what other SQL developers in the industry do, whether there is any best practice on this, or whether we are unusual. It has to do with creating dependencies between views, i.e. joining them to each other, as well…
-
An interesting coding problem
When programming, it’s actually quite unusual to come across a requirement that is intellectually interesting to work on. Most are something along the lines of ‘grr, why doesn’t this bit of code work, I can’t see anything wrong with it?’ or ‘I need to add another option into this settings screen and plug it in…
-
Learner Progression BETA
Bath Digital Festival A quick non-feature update: we’ll be appearing at the Bath Digital Festival on 12th July this year – we hope to see you all there! Login page The first thing anyone will notice if they log in via www.agilebase.co.uk is that the login page has been updated. We’ve decided to highlight prominent…
-
Colour swap option and chaser fix
A new version of Agilebase has been released today which includes two updates. The first is a fix to a problem with chasers, the main reason for the quick release today. People were finding that they were unable to respond to chasers – they were getting an error message when attempting to upload a file…
-
Citizen Developer Focus
This year a lot of the focus is going to be on Learner Progression for Agilebase – building the pathway which allows beginner Citizen Developers to progress to become Software Architects. That will involve training materials, community events etc. as well as features. In preparation, we’ve had a second look at a few developer features…
-
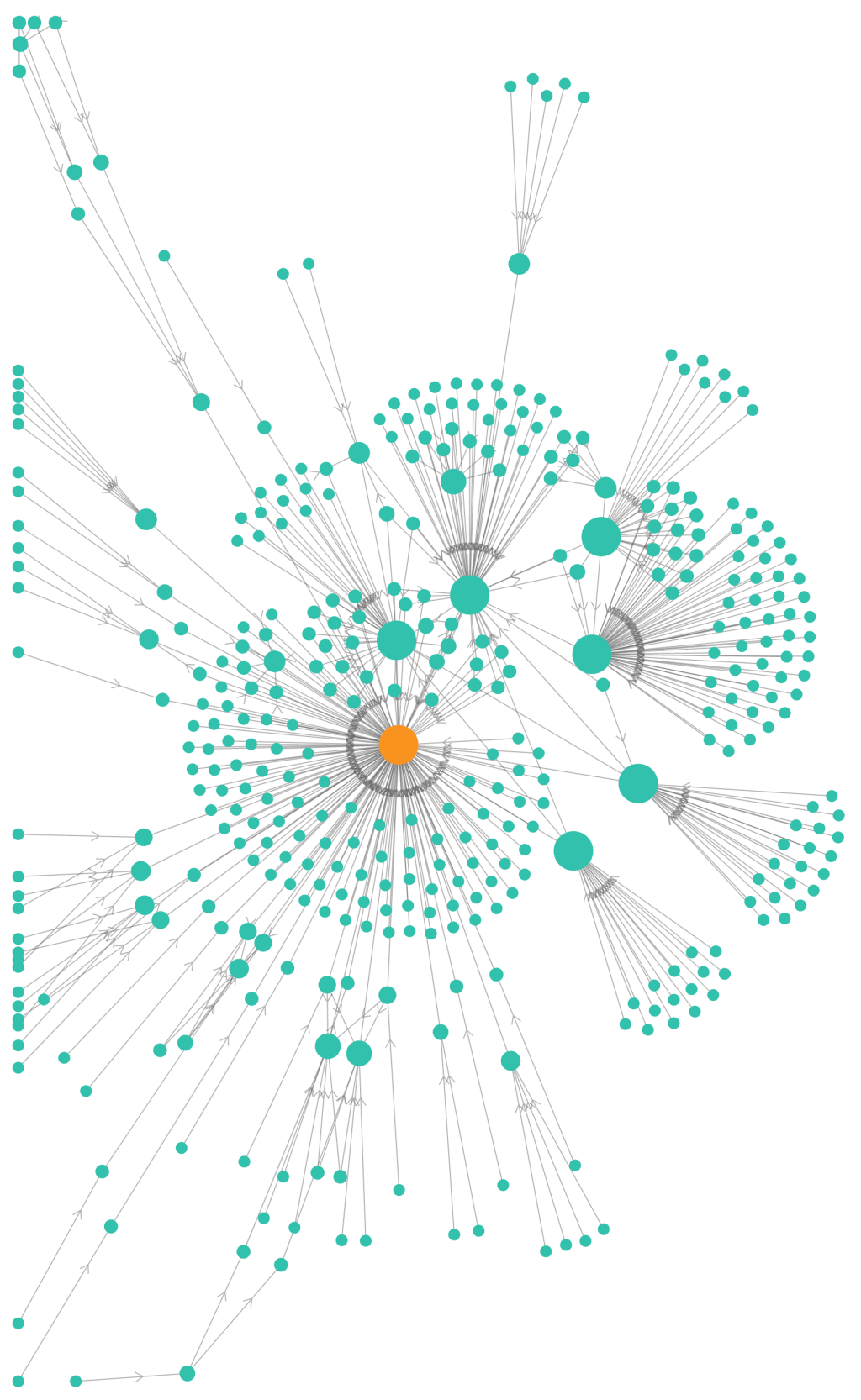
Visualising data connections
(BOMs and other recursive data structures) What’s a BOM? It stands for Bill Of Materials and basically means a list of the constituent parts of something. It’s one of the types of data structure that can be built in Agilebase. The interesting thing about BOMs is they can be recursive, i.e. self-referencing. Here are a…
-
November 2022 Technical Update
Agilebase is delivering what you asked for New features are rolling out soon Following our big Learner Progression release last month, we’ve taken some time to round things out a bit and make some features much easier for learners to get to grips with (as well as being quicker to use for seasoned developers). Creating…
-
Agilebase v6 – Updated framework that will make your teams agile
3rd November 2022 It’s been slightly longer than usual since our last AgileBase platform release, which was back in August, but that’s because we’ve been working on some significant functionality, enough for a new major release. We are excited that AgileBase Version 6 will be ready soon and is available for you to test now.…
-
agileBase importing improvements
This week a number of usability and functionality improvements to the spreadsheet import facility have been made. Many spring from ideas our friends at Argenta have suggested while working on one of their agileBase projects. These improvements will go live on Monday. There is a new option ‘use default values’ available when uploading new data…
-
agileBase news: test servers and language support
Test servers Many larger organisations who use agileBase have their own test servers. This is a service we provide to let people test out changes before making those changes on their live system. This is particularly important where their live system is mission critical. However, until now, this service has been relatively basic and ad-hoc.…
Got any book recommendations?
