Agilebase platform blog: recent updates
-

Artificial Intelligence Updates
Last month’s release of beta AI features into Agilebase prompted the most great feedback we’ve had in a while. People were excited by the possibilities: A lot of ideas were sparked, too: and one important concern: We’re pleased to report that many of the above ideas have now been implemented! However, to address the data…
-
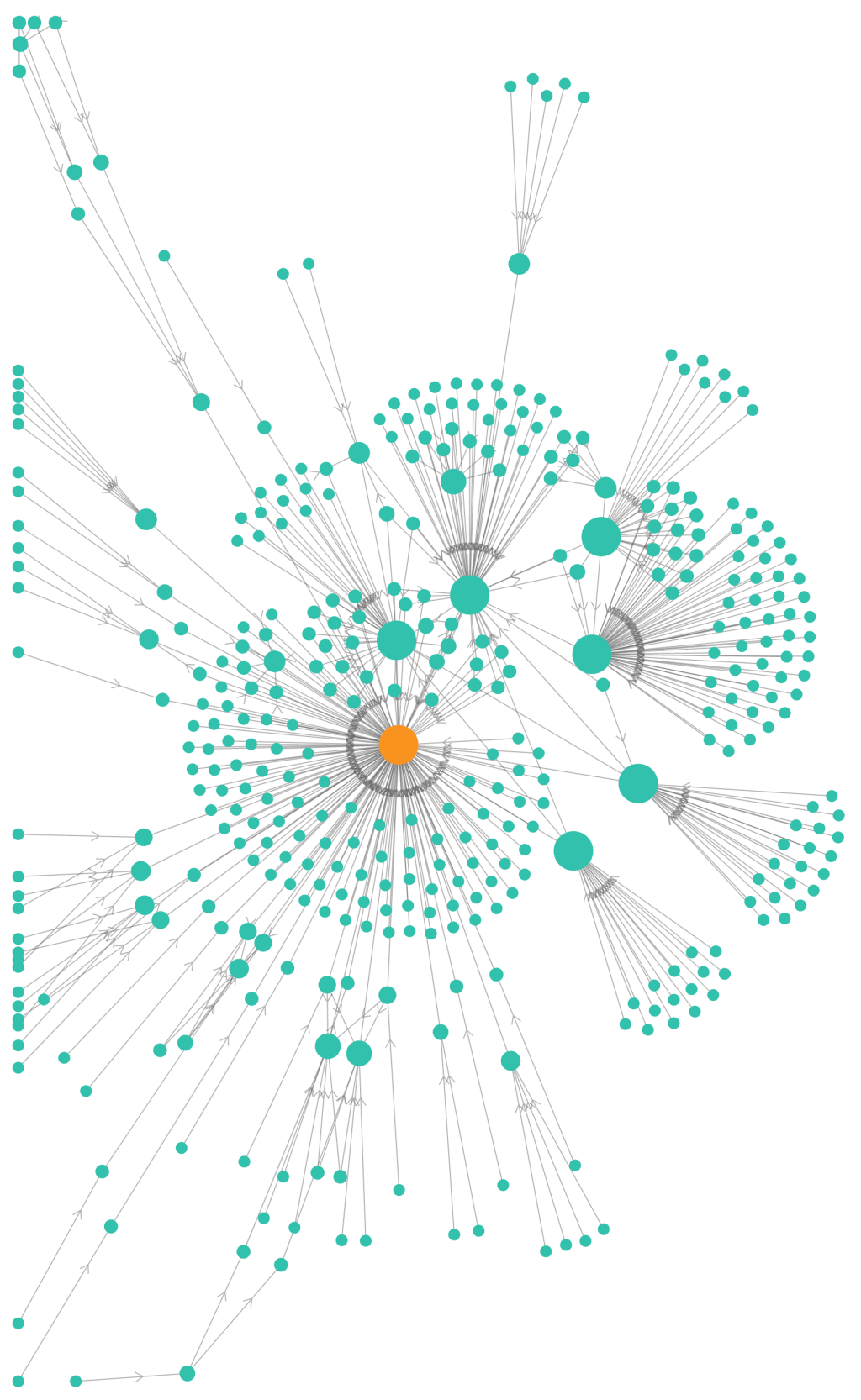
Agilebase AI Assistant
Over the past year we’ve watched as artificial intelligence systems have wowed us with amazing capabilities. Here’s just one example: AI obviously has the potential to be revolutionary in many fields. For Agilebase, we’ve gathered lots of great ideas, not least from speaking to customers, and tried out some fun tests. We’ve also heard about…
-
Disabling accounts
Here’s one update administrators should be aware of, coming soon: As part of our continuing efforts to ensure data security and privacy keeps up to date with current best practices, we’ve reviewed our codebase and functionality against the most recent OWASP Secure Coding Practices Guide https://owasp.org/www-project-secure-coding-practices-quick-reference-guide/stable-en/ Most items in the checklist have already been addressed,…
-

November Agilebase platform updates
Various platform enhancements have been released since the last update in September, small tweaks but making a big difference in usability for some people. Mapping improvements PDF document generation improvements User interface improvements Developer improvements
-
Join us in Bristol: The Rise of No-Code Development
Interactive session with networking In a world where technology is rapidly evolving, so too are the tools and methods we use to interact with it. Gone are the days when coding was the exclusive domain of programmers and developers. Today, we stand on the cusp of a new era in software development – the era…
-
Number visualisations (and other updates)
Today’s platform release contains some new features but also the removal of some old unused bits of code. That’s a good thing to do every now and again as it makes the system easier to work on, more bug-resistant and quicker to develop in future. Without further ado, here’s the rundown of new features added…
-

Agilebase on phones
We’re pleased to announce a refresh of the Agilebase user interface for mobile phones and tablets. The goal is to allow Agilebase developers to create apps for specific purposes which are easy to use on a mobile device. It’s important to note that it’s not to magically make every application built with Agilebase suddenly be…
-
Crisis Coding
Once in a while (a long while hopefully), an emergency occurs and the software that a customer relies on starts failing. Here’s a little write-up of what that’s like, what we can do and how improvements can be made that improve system resilience for everyone. This isn’t something that people tend to speak about much,…
-
Agilebase new features
A couple more nice improvements have been added to the Agilebase platform since our last update near the beginning of the month. These are Calculation precision option For decimal number calculations, you can now select the precision the calculation outputs at, e.g. 0.5 is 1 decimal place, 0.53497 is 5 decimal places. Similarly, you can…
-
Agilebase – recent improvements
It’s come to my attention that we’ve not published an update about Agilebase features recently, since the last in April. That’s largely because we’ve been focussing on preparing for the Bath Digital Festival – please do come and see us on the 12th July. Sign up with Eventbrite here. However development has continued apace. Here…
Got any book recommendations?
