Agilebase platform blog: recent updates
-

Back button and other Agilebase updates
The Agilebase platform has been progressing steadily over the past few months, in areas such as usability and accessibility. The following updates will become live in the next couple of days. The most noticeable change to users for this release will probably be the removal of the ‘back’ button from the navigation bar at the…
-

AI Workflows – calling beta testers
Generative AI has been used in Agilebase for some time, with various features to help developers of systems, like We’re now adding the ability for customers to use AI directly and have it operate on the data in their systems. We are opening a two month limited beta testing programme for individual customers who can…
-

August 2024 enhancements
Often in-between work on major features (e.g. AI), we take a beat to work on all the great ideas that customers and partners have come up with, as well as squashing some bugs that have been reported. This month’s release is one of those – some nice usability improvements and important bugfixes. New Features Workflow…
-

OpenAPI
It’s been interesting working more with IT specialists as partners recently, who use Agilebase to deliver projects to customers. Their concerns are sometimes different to those of customers. An important part of the value that partners add is in helping integrate Agilebase with a wider ecosystem of software. For example when building a stock control…
-

AI, data security and new features
I always have a problem when writing about new features and news for Agilebase – there’s always something exciting on the horizon or in progress, it’s easy to think “I’ll just wait until we’ve done that, then we can tell everyone about it”. However I think we’ve had enough good things since last time that…
-

Using AI to speed up No Code
One thing that No Code can do very well is speed up the creation of software, to the point that you can often do it in real time alongside end users or customers. There are still a couple of common bottlenecks though. Firstly, when confronted with a new project and a completely blank screen, it…
-
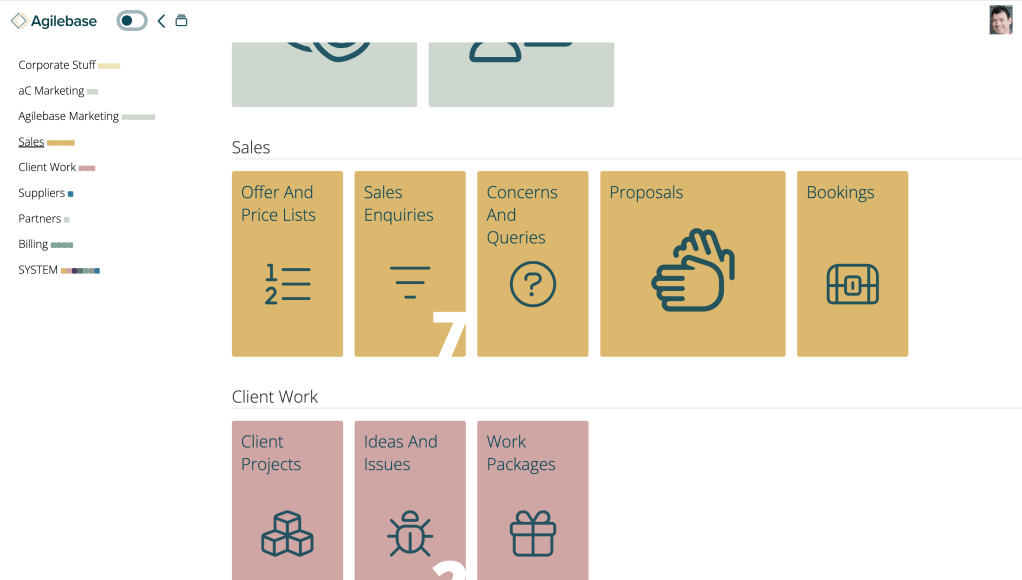
Sections navigation
You may notice a very visible new feature when you log in to Agilebase, at least if you have lots of tiles in sections on the homepage. On the left hand side of the screen, a navigation menu appears. Clicking a name (e.g. ‘Sales’ in the screenshot) will take you directly to that section of…
-

No Code != No Thought
Why does it still benefit to have seasoned developers involved in a No Code project? People often think using because there’s no code you need no coders. But for complex projects, the architectural experience those people have can be a great benefit. The No Code advantages of rapid development time and the ability to build…
-

Lots of platform updates for April
Since our last news in February, we’ve implemented 53 improvements (both ideas and bugfixes) to the Agilebase platform, many in response to customer requests. I will pick out the highlights and any important ones here, and try to give a very brief explanation of each. These will be released to the live server in the…
-

More intuitive workflows and APIs
You may have noticed that a lot of our work recently has been to do with AI, and that is very exciting. However, we’re not neglecting the un-sexy but important work of continuously improving the No Code developer experience in general. We have just released one of those improvements to do with using some of…
Got any book recommendations?
