Agilebase platform blog: recent updates
-
New updates
New Agilebase release notes and updates are now being posted at – https://agilebase.co.uk/news/ Please follow there to keep up to date.
-
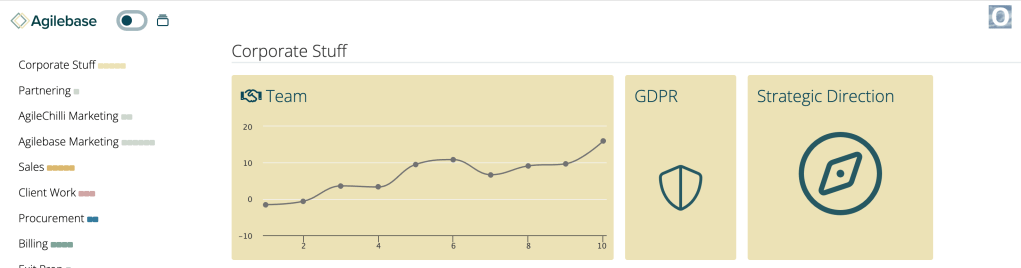
Calendars and charts
I’m not sure of what the best word is to describe the theme of this week’s Agilebase release. It’s taking existing features and user interface components and making them available in a wider variety of contexts. In short, fleshing out the user interface capabilities and making the platform more rounded. Not being able to concisely…
-

Recent Agilebase improvements
One of the projects we have on the go here at Agilebase is to make our development process a lot more transparent – we’ll be showing customers the ideas and issues they’ve reported, so they can see how many other people also have requested similar things. Release notes like these will be largely automated. I’ve…
-

No Code project success
A slightly different post today, rather than delve into the new features in Agilebase (which we’ll have to do soon as there are quite a few!), we’ll take a step back and look at the entire journey of a No Code project. From when you start as a new customer to years down the line,…
-
Agilebase infrastructure upgrades
Customers may like to know that we’re upgrading the Agilebase infrastructure, to generally speed up the system, make it more reliable and also ensure that as we grow, we can keep on top of monitoring and data security. Technical Details If you’re interested in these, read on. If not, feel free to skip to the…
-

New AI workflows and GDPR
New AI workflows Agilebase is now able to call on AI to both create and update data in your system. You can use existing data to feed it prompts, and have those act, automatically, on data in bulk. If that seems a bit abstract, an example should help bring it to light. You can think…
-

Simplified API calling
We’re making API requests even easier to prepare for programmers. Firstly, please note that the current (or now, old) way of making API requests remains in place – no existing APIs are going to break! The new style operates alongside the old and is described if you tick ‘use API’ in the ‘workflow – API’…
-

Using DeepSeek and other models
A quick note to all Agilebase administrators. You may have noticed the brouhaha about DeepSeek in the news recently, the new Chinese AI model that is competitive with the best to date, but at the fraction of the training cost: https://arstechnica.com/ai/2025/01/china-is-catching-up-with-americas-best-reasoning-ai-models/ As DeepSeek is an ‘open source’ model, anyone can run it on their own…
-

AI Roadmap update
A bit of a different update today – as well as letting you know what’s new in Agilebase, we’ll look forward to how we see the year taking shape – we have an exciting roadmap for AI features and also events! We think that 2025 will be the year of AI realism – certainly here…
-
Drag and drop file uploads
Just a short update for today’s release – along with a few minor bugfixes and usability improvements, there’s one significant new feature added: the ability to drag and drop files onto file upload buttons, to upload them. That’s it! One of our briefest updates ever, but there’s plenty more interesting stuff we’re working on to…
Got any book recommendations?
