This week we have been asked by a customer to do a bit of work that’s interesting enough to write a blog post about – always nice!
Preventing or removing duplicates is a common requirement in CRM systems and other database apps. With a multi-user system, it’s not uncommon for two different people to try to add the same company details twice for example, without checking whether they’re already in the database.
On the prevention side, there are a couple of features of agileBase which help. The first and most obvious is the unique option for fields. With this enabled on a company name field for example, people will be prevented from entering the exact same name twice. If appropriate this can be slightly improved by also turning on the text case option to force all entries to the same case as they’re entered.
However, even this isn’t going to catch all duplicates. Company names can often be entered slightly differently, e.g. with ‘Ltd’ or ‘Limited’ following the name, the word ‘The’ at the start or with different punctuation.
To catch these, the build in duplicate detection can be used, activated for all record title fields. When someone enters a name, the system automatically searches all existing records for any similar names.
Reporting existing duplicates
Even with all these features we will often still want to find duplicates that in one way or another have made their way into the system. Maybe the data hasn’t been manually entered by staff, but imported, e.g. from spreadsheets, or via an API from other software or a website. However, in our case, the cause was the merger of two different business units and their data.
Finding ‘close match’ duplicates is an interesting problem that can be solved in a number of ways. Here’s a short introduction and there are many articles and papers which go into the mathematical details of various methods.
We chose to use trigram matching, an approach which is supported natively by the database agileBase uses, PostgreSQL and which is fast and effective. As they say, “this simple idea turns out to be very effective for measuring the similarity of words in many natural languages”.
A trigram is a set of three consecutive characters, for example ‘agileBase’ would contain ‘agi’, ‘gil, ‘ile’, ‘eBa’, ‘Bas’ and ‘ase’. There are some further considerations, for example how to treat the starts and ends of words, which are explained well in the PostgreSQL documentation page.
In brief, we simply count the number of trigrams two words or phrases share as a proportion of the total number.
Our goal
So as a concept, what we want to do is compare every company name in our database with every other company name, get a similarity score from the pair and sort the results in order of descending similarity, with a cutoff to stop showing results once they fall below a certain similarity threshold.
An immediate thought is ‘how many comparisons is that’? Well, the database we’re looking at currently has 13,000 companies in it. That would mean 13,000 ^ 2 = 169 million comparisons. Ideally, we’d like the system to continue working well as the number of records significantly grows. At 100,000 records, the number of comparisons would be ten billion.
As this ‘naive’ number of comparisons is the square of the number of records, we’d like to get that down as much as possible in order for performance not to suffer.
We can immediately cut the number in half – if we’re comparing Company A to Company B, we don’t then also need to compare Company B to Company A.
We can also use the fact that duplicate names are very likely to start with the same letter. There are some exceptions, for example Bristol University and University of Bristol (only the latter is correct!) however that will be uncommon and the tradeoff is likely to be worth it. To take advantage of this fact we will also need to strip any common prefixes from the names to compare, for example ‘The’ as in ‘The University of Bristol’.
Assuming an even distribution of first letters, the number of comparisons would be
(((n/26)^2) x 26) / 2.
(also taking into account cutting the number of comparisons in half as above).
For 13,000 names, that would result in 3.25 million comparisons, down from 169 million. For 100,000 it would be 192 million, down from 10 billion. Still quite a lot, but we can give that a go and see how it works out.
Actually, thinking about it, if we import more sets of data from other sources in future, we will only need to compare the newly imported companies with all others, not do a full comparison of everything with everything. So I don’t think we’ll ever get anywhere near the top end of those numbers.
There are other reduction methods you’ll be able to think of – for example, comparing only those where postcodes are the same (assuming each company has only one address, or HQ details are all filled in). However the above is what we went with.
Implementation
Ok. Let’s move on to making this work.
Our first step is to create two views, which we can then compare with each other. Each view will have the ‘cleaned’ version of a company name and the first letter of that name. Let’s add two calculations
simple name =
regexp_replace(
lower({a) companies.company name}),
‘^the\\s’,
”
)
first letter =
substring(
{simple name}
from
1 for 1
)
These calculations use SQL to
- convert the name to lowercase and strip any leading ‘the’
- extract the first letter of the resulting ‘simple name’
Once we have these two views, which we’ll call ‘similarity check 1’ and similarity check 2’ we can join them together and do the similarity calculation.
From similarity check 2, we add a complex join on the ‘first letter’ calculation to the first letter calculation from similarity check 1.
Then also in similarity check 2, we can add a boolean (true or false) calculation to allow us to cut the number of comparisons in half:
first comparison = {similarity check1.id:companies} < {companies.id:companies}
(here, the name of the table containing the company names is, well, ‘companies’). This calculation outputs true if the company on the left hand side has a lower internal ID than the one on the right, or false if not.
We now just add a filter on that calculation:
first comparison = true
Now to the similarity check itself, which is simply
similarity =
similarity(
{similarity check 1.simple name},
{similarity check 2.simple name 2}
)
All of this has been in the ‘similarity check 2’ view. We now have all the information we want to look at in one place. Well, almost – for people to actually use the system, they’ll probably want to look at the actual company names, not our simplified versions. They may also want to see other information, like perhaps the account manager for each company.
So we’ll create a third view, just called ‘company duplicates’, which pulls in the calculation from ‘similarity check 2’ but displays things in a more user friendly manner.
‘company duplicates’ joins to similarity check 2 on the internal company ID. We then sort and filter on similarity, using a filter ‘similarity > 0.7’ in our system.
I’ll leave the details of adding additional fields such as account manager etc. It is worth noting that to speed things up for users, we set ‘similarity check 2’ to cache its results. On our dataset it takes a few seconds to load – with the results cached, users can view and search the data with better responsiveness. The load on the system is also reduced.
Here’s what the results look like (details have been changed or pixellated, but you can see the first couple of example names compared.
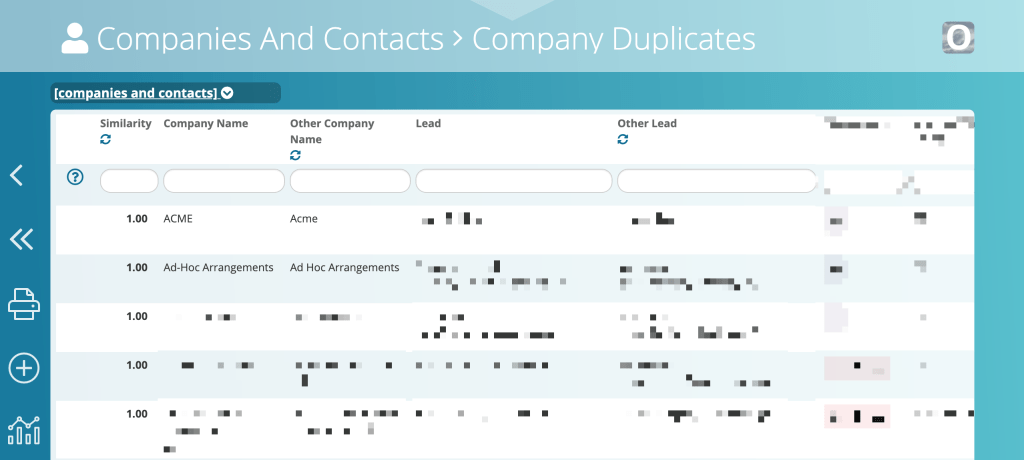
Hopefully this can act as a useful pattern for people to follow if they want to do similar de-duplication work.
The next step could be to tackle the process of actually merging and deleting records once duplicates have been identified. For example, workflows could allow details of two company records to be automatically merged together. However that is a task for another day!

Leave a comment