As we mentioned last week we’ve upgraded some of the server software the agileBase platform uses. The most significant upgrade is a move from PostgreSQL version 9.5 to version 10. That’s the database that stores all of agileBase’s data.
Now that it’s been running for more than a week, we can see whether there are any differences in performance. It’s common to see benchmarks which are designed to replicate real-world scenarios, but not so common to see actual speed changes for live production systems.
So here’s a simple before and after comparison for our own system. The method we used is to look at the top 30 queries from before the upgrade which were taking the most time in total over a 7 day period. That’s not necessarily the slowest queries, we’re measuring the total cumulative time spent running a particular query over those 7 days. So many of them will be the slowest queries but some will be faster ones which are just used very frequently. We then compared the average times with those for the same queries in a 7 day period after the upgrade.
The takeaway is that for us, SQL querying has become significantly faster, in fact the top 30 most time consuming queries are faster by an average of 35%. Of course this can’t be generalised to anyone other than us and even then the nature of a live system means multiple factors could be at play – see below!
To find these stats we used the JavaMelody monitoring package.
Caveats
Please note that this analysis is only meant to inform us internally, it’s not necessarily rigorous enough to draw general conclusions from. For example, the system may be under different usage patterns from one week to the next (different users going on holiday etc.). It’s also possible the data in the system has changed – for example if someone’s done a large data import. No doubt there are many other possible differences. One advantage of an artificial benchmark is that it’s more repeatable!
Another thought – if we wanted to spend more time on it, we could also compare the top 30 most time consuming on the new with the old, which may be a different set of queries. We’ve done some spot checks to confirm that many of the top 30 queries do overlap though.
With those things in mind, here are some general stats and the results.
Overview stats
Just to give some background, some general statistics from the first 7 day period are:
- there were 2,769 unique SQL queries (counting the same query with different parameters as one query, i.e. counting the ‘prepared statement’ versions)
- there were 7,052,363 calls to those queries in total
- the average time to process was just 5ms (five thousandths of a second) for 98% of those calls
- the slowest 1% of calls took on average 302ms each
The stats for the second 7 day period were very similar apart from one big difference -there were about 3 million calls less in total. That’s partly because some external apps were previously calling the system APIs in bursts every 5 minutes 24hrs a day (reduced a couple of days before the upgrade) and also because the need for another type of internal query was reduced due to a cache implementation. It’s possible this could have had an effect on results but I think a material change is unlikely due to the fact the server isn’t CPU-core-bound (there are plenty of unused cores most of the time), backed up by the fact the other average time stats remain the same. Furthermore, some of the query times were manually spot checked before the upgrade at times of low activity and remained similar. It’s impossible to know for certain though.
Results
| Query no. | Old PG9.5 (ms) | New PG10 (ms) | Speedup* | Query description |
| 1 | 62 | 31 | 1.0 | retrieve comments for a field |
| 2 | 898 | 768 | 0.2 | retrieve a filtered list of sales jobs |
| 3 | 382 | 371 | 0.0 | retrieve the newest customer leads |
| 4 | 230 | 193 | 0.2 | retrieve a filtered list of trade jobs |
| 5 | 255 | 154 | 0.7 | retrieve contact details for a lead |
| 6 | 794 | 555 | 0.4 | search the list of allowed products for an order |
| 7 | 324 | 232 | 0.4 | find duplicate orders for a customer on the same day |
| 8 | 53 | 40 | 0.3 | retrieve sales contacts for a company |
| 9 | 223 | 234 | 0.0 | retrieve the account info for a lead |
| 10 | 2234 | 1694 | 0.3 | total up the gluten values in all recipes |
| 11 | 75 | 48 | 0.6 | retrieve the list of lead activities requiring an email to be sent |
| 12 | 204 | 202 | 0.0 | retrieve a filtered list of active trade jobs |
| 13 | 614 | 545 | 0.1 | retrieve a filtered list of current sales jobs |
| 14 | 605 | 414 | 0.5 | retrieve a filtered list of all leads |
| 15 | 56 | 21 | 1.7 | search the products list |
| 16 | 673 | 557 | 0.2 | retrieve the list of order lines to lock |
| 17 | 91 | 71 | 0.3 | calculate finance costs for a job |
| 18 | 127 | 127 | 0.0 | calculate the message for a product sample |
| 19 | 817 | 667 | 0.2 | retrieve a filtered list of all jobs |
| 20 | 119 | 120 | 0.0 | retrieve a filtered list of all calls |
| 21 | 19 | 15 | 0.3 | retrieve customer account info for a sale |
| 22 | 208 | 347 | -0.4 | total up the quantities in a recipe |
| 23 | 203 | 172 | 0.2 | create activities for expired memberships |
| 24 | 202 | 173 | 0.2 | create activities for 30 day renewals |
| 25 | 24 | 20 | 0.2 | retrieve a filtered list of accounts |
| 26 | 1100 | 594 | 0.9 | retrieve the newest wholesale customer orders |
| 27 | 730 | 298 | 1.4 | get the audit trail change history for a record |
| 28 | 13789 | 11122 | 0.2 | refresh the materialized view of confirmed invoices |
| 29 | 320 | 267 | 0.2 | retrieve a particular user’s list of filtered leads |
| 30 | 1361 | 959 | 0.4 | retrieve a list of invoices to auto-generate |
*The speedup column is calculated as the ratio of the old over the new, minus 1. Hence a speedup of 0 means the query performs exactly the same after the upgrade. 1 means it’s twice as fast, 2 means it’s three times as fast. A negative figure means it’s slower, as you can see there are one or two which are slower, but the vast majority are faster, often significantly so.
Here the query descriptions are only vague and massively simplified explanations of a particular query. Many of these are the slower queries and are typically very complex, with lots of joins to multiple layers of views, aggregate calculations etc. A couple are simple but just called very frequently. Some may work on many millions of records, some a few thousand – there’s a good mixture!
Charting the actual average query times before and after didn’t work very well because of the massive difference of speed between some queries. A log scale might have helped but that would make before and after comparisons less readable.
Instead here’s a chart of the speedup factors (x-axis, see above for definition) for each query after the upgrade. The y-axis is just the query number from the table above.
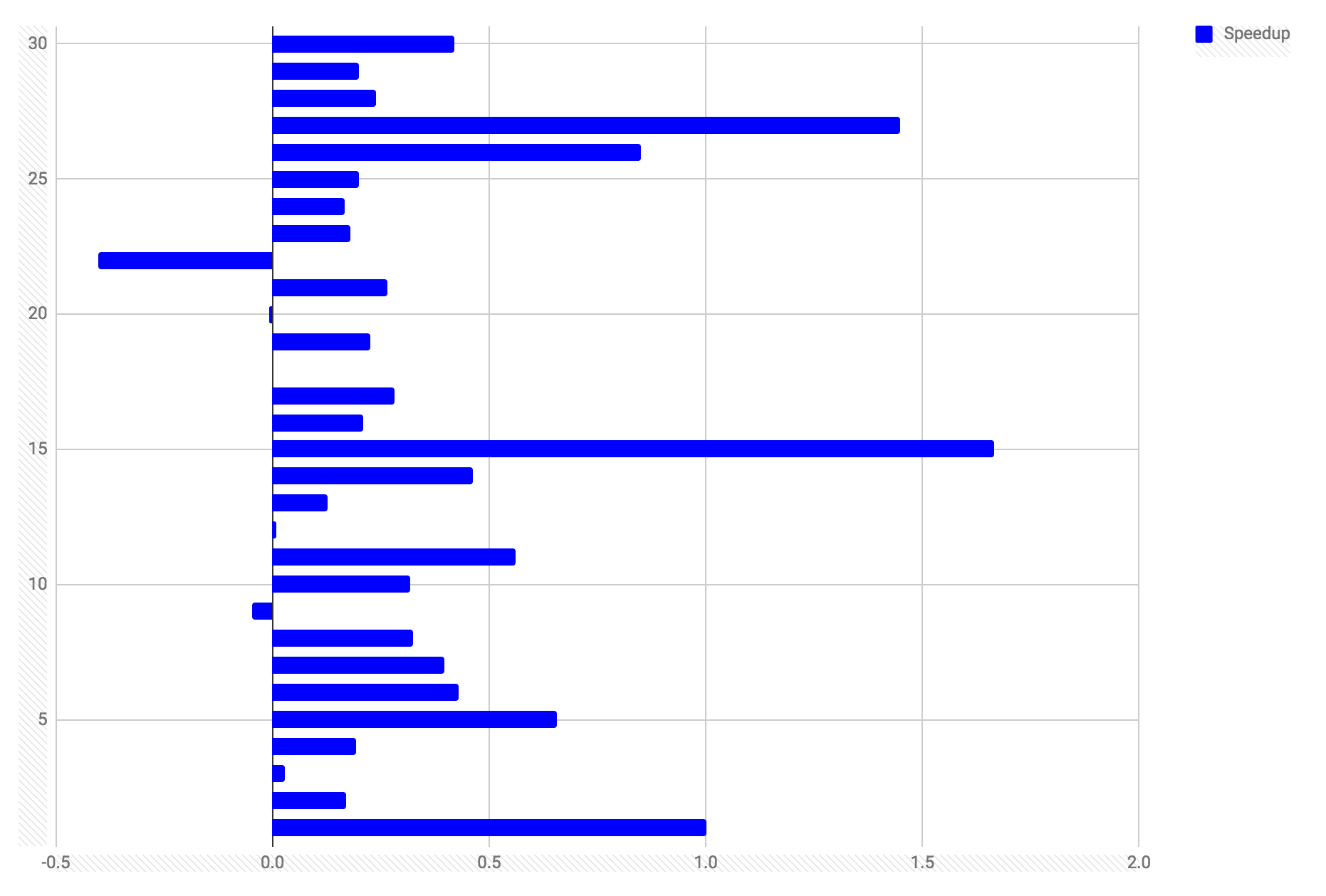
The average query speedup is 0.35, i.e. queries are 35% faster after the upgrade. That’s a pretty significant speedup, all without a single hardware change. Thanks to the PostgreSQL project team for continuing to work hard on performance enhancements as well as many other areas – it’s a vibrant community. These improvements are certainly appreciated.
Configuration notes
You may be wondering about configuration – as we say, no hardware was changed. This machine has 64GB RAM and 16 CPU cores. The only difference in PostgreSQL configuration was the addition of three new parameters for the newer software to allow the system to take advantage of multiple cores while processing a single query, i.e.
max_worker_processes=14
max_parallel_workers=12
max_parallel_workers_per_gather=2
It’s possible that future configuration changes, e.g. allowing greater parallelism could improve things even further.

Leave a comment