Here’s a blog post to act as a question for the PostgreSQL community. I’d love to know what other SQL developers in the industry do, whether there is any best practice on this, or whether we are unusual.
It has to do with creating dependencies between views, i.e. joining them to each other, as well as refactoring them.
PostgreSQL views in our apps tend to be very inter-connected and de-composed. Rather than having one large query, it will often be split up into constituent parts, each part a separate view. There can be many levels – although not quite ‘turtles all the way down‘. See below for some diagrammatic examples.
Below are some of the reasons for this, along with the problems and techniques we use while dealing with them. My question is, how many others are dealing with similar concerns and if so, how?
The frequency with which we and our users build complex view structures may have something to do with the fact the SQL is created not by hand, but using our No-Code platform Agilebase. Or perhaps it’s a general type of thing that many do?
Firstly, to explain the types of scenarios I’m talking about. Why would you split a view up into parts then join them together again? There are a few reasons.
Reason 1 – preventing result multiplications
For many views, it’s a requirement for correct operation. In particular, when you want aggregate calculations from multiple other tables/views in the same view, you need to avoid double counting. Say you’re creating a view to return two values to the user, the total sales to date for a customer along with the total number of people you deal with there. You have three tables:
- customer organisations (organisations)
- customer contacts (contacts)
- invoices (invoices)
To get the number of staff, you’d do something like
SELECT organisations.name, count(contacts.id)
FROM organisations
LEFT OUTER JOIN contacts ON contacts.organisation = organisations.id
Now to add in the total sales value, would you amend it?
SELECT organisations.name, count(contacts.id), sum(invoices.value)
FROM organisations
LEFT OUTER JOIN contacts ON contacts.organisation = organisations.id
LEFT OUTER JOIN invoices on invoices.organisation = organisations.id
No, you wouldn’t, as that would make your calculations come out wrong. If you had three contacts for an organisation, the sum(invoices.value) would be three times what it should be.
This is a well known issue/feature in SQL, see e.g. this Stack Overflow question. There are may ways you can address this, we typically suggest customers create separate views, resulting in SQL as follows
CREATE VIEW contacts_count AS
SELECT organisations.id, organisations.name, count(contacts.id) AS contacts_count
FROM organisations
LEFT OUTER JOIN contacts ON contacts.organisation = organisations.id
CREATE VIEW invoice_values AS
SELECT organisations.id, organisations.name, sum(invoices.value) AS invoices_total
FROM organisations
LEFT OUTER JOIN invoices ON invoices.organisation = organisations.id
and then the final view we want
CREATE VIEW totals AS
SELECT organisations.name, contacts_count.contacts_count, invoice_values.invoices_total
FROM organisations
LEFT OUTER JOIN contacts_count ON contacts_count.organisation = organisations.id
LEFT OUTER JOIN invoice_values ON invoice_values.organisation = organisations.id
Developers using Agilebase don’t actually write the SQL, it’s generated by the software, so for any customers reading this, don’t worry, this is just what’s going on under the hood!
Reason 2 – multiple uses of a calculation
What if our invoices_total calculation is actually required in many different places? It may be in KPI view, in operational debt recovery views etc. It makes sense to just create the calculation once in a single view, then reference it from wherever you may need it.
If the calculation is really complex, not just a simple sum(), then that’s an even better idea. If you need to tweak or improve it later on, you only need do so in one place. Plus you avoid the possibility of making a mistake when creating one of the copies otherwise.
Reason 3 – ease of comprehension
Sometimes, when you’ve got a very large view with lots of calculations, it can make sense to treat each one separately. Maybe you like being ultra-organised and create different views for different subsets of calculations. Or maybe the complexity makes it quite a slow view and it’s easier to work on one part at a time (or debug) before adding each into the whole.
Examples
Here are some diagrams of the joins between views, taken from actual customer systems. In most cases, the customers themselves have built these. The views in question are orange, the ones they join to green.
To start with, here’s a simple view of non conformances (NCs). When a company accepts goods in, any faults can be raised as an NC. For example, a bag of widgets is received and one of them’s broken, or some of the packaging is damaged.

As you can see, ‘NCs – all’ receives data from two joined views:
- nc – calculate grading, which calculates how serious the non conformance is based on various factors
- nc stats – counts open, which counts how many actions against each NC there is. It’s made up of two parts
- NC – count of PAs, which counts how many preventative actions have been logged, to stop the same thing happening again in future
- NC – count of CAs, which counts how many corrective actions there are to address the individual NC specifically
Moving on, here’s a more complex example, a view to show costs when generating quotes for customers, for bespoke recipe development projects for a company in the food sector.
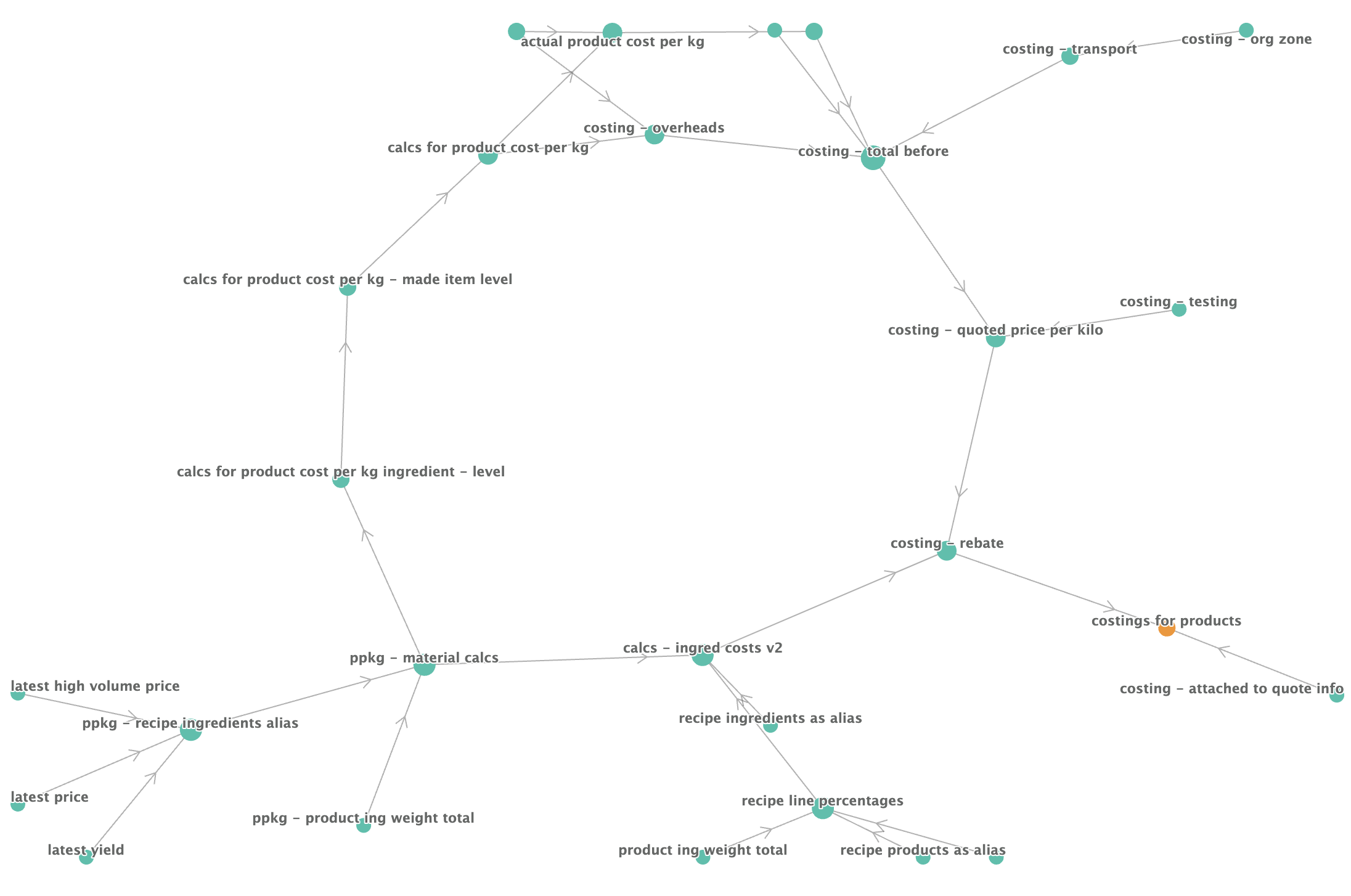
I’ll leave that one up without comment – you can see that costs have various contributions, from the ingredients in a recipe, packaging, transportation etc. Frankly, I’m not qualified to comment further!
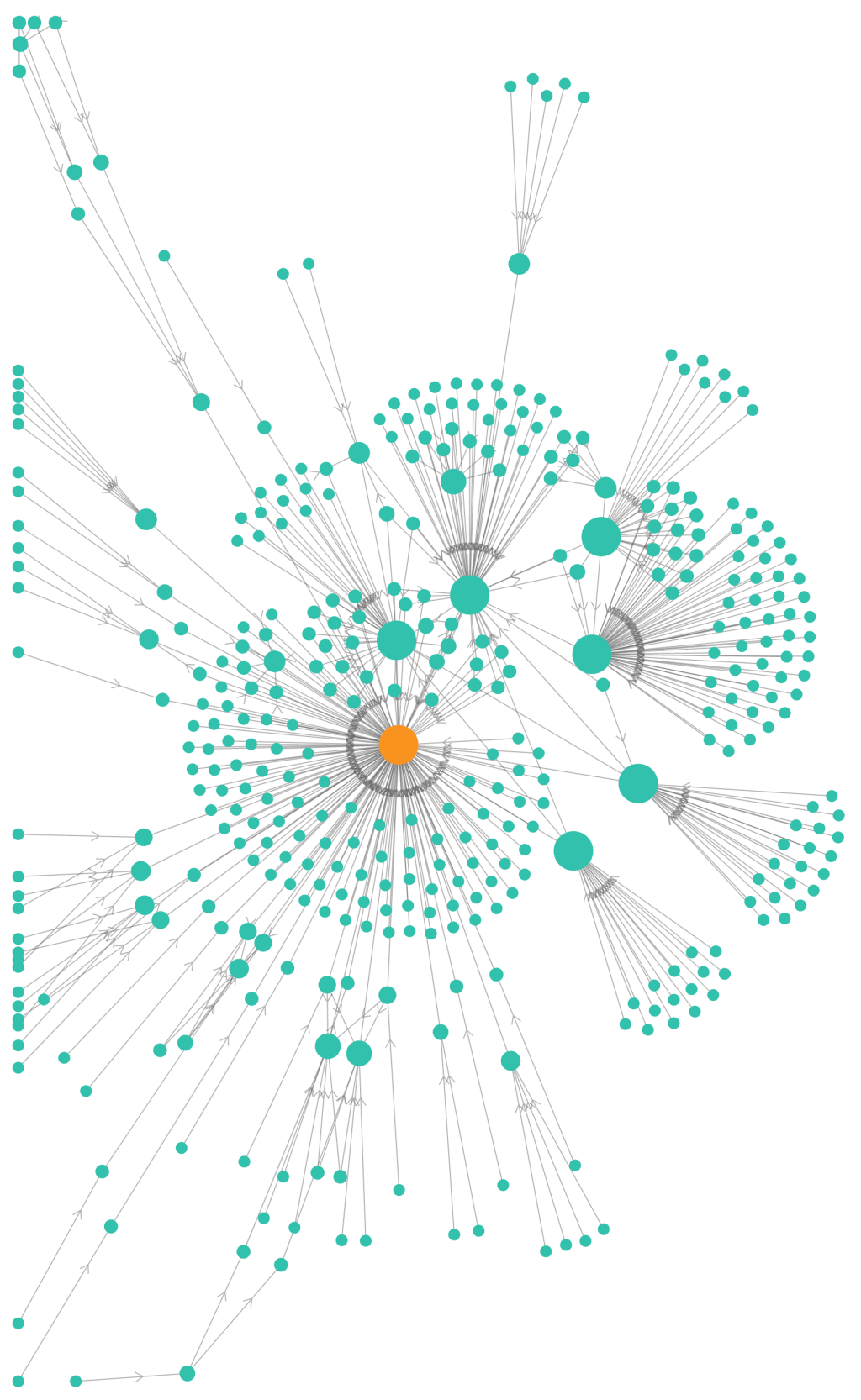
Finally, here’s an example in the other direction. Rather than showing what feeds into a particular view, this shows which other views join to our view in question. In other words, we have a calculation, where is it used?

In the centre is the view in question, which calculates the amount of finance due to be repaid by each customer of a sales company. That feeds into multiple departmental views.
As you can see, outputs from that single calculation view is used in so many places it would be hard to count manually! Imagine having to update the calculations in all of those views – there’s no option other than to centralise.
Potential Problems
Performance
One issue that people may immediately think of is performance. Will chains of joins slow down database queries?
It may or may not. Planning time might increase and in some cases, we may exceed PostgreSQL’s from_collapse_limit or join_collapse_limit parameters, resulting in potentially non-optimal plans. This is a subject which lots of other people have written lots about, if interested, I’d suggest googling those terms.
However, there are many ways we can look at increasing performance in PostgreSQL and it’s sometimes quite a fun problem solving exercise to do. It’s always rewarding to get a speedup of multiple orders of magnitude, which can happen. Some examples of speedup techniques are
- the use of indexes
- materialized views (i.e. caching some of the lower level or intermediate views)
- partitioning
- careful selection of datatypes
- the use of a tool such as Citus Data when you have really big data
amongst many others. Its a whole topic in itself.
I’m of the view (and this is reasonably well understood to be best practice I believe), that you should first optimise for ease of use, readability etc., i.e. don’t sacrifice those things for the sake of performance.
Refactoring ability
Significantly though, and this can be a big iceberg in the sea of database maintenance, is what do you do when changes are necessary to dependant views?
With PostgreSQL, if you have a view A, which other views B, C, and D join to, you can only make certain changes to A easily. You can update a column which is a single calculation for example. However if you want to add or remove fields (columns) from A, you first need to drop B, C and D, make your change, then create them again afterwards.
For Agilebase, we’ve put a lot of work into automating that process. In fact, I’d probably say this is the single biggest advantage the platform gives you, if you’re talking about database-specific concerns. For example, the system either rebuilds everything in a single transaction, or if it estimates that will take too long to be reasonable (a small fraction of the transaction timeout limit), drops all dependancies and recreates them (in the right order) in the background, first setting an application level lock to stop people querying them, whilst displaying maintenance messages instead.
For massive changes, it’s obviously a good idea to use a test system, then roll out to live in a planned fashion.
Theme – refactoring
A summary can be made which will be familiar to any coders amongst you. The general theme is refactoring. When programming, you’ll often split up one large function into smaller parts, for ease of maintenance and understanding, either at design time or as time goes on and a system becomes more complex.
I’d argue the same goes for database design work. I’m seeing more and more similarities – when complex systems are built up, ease of comprehension becomes more and more important.
The big question I have is how do other database developers do things? The examples above, and many more I could show, are from systems that customers have built – most of the time I have no input, so it’s interesting to see these themes develop.
Personally, if I had to build a complex system and I wasn’t able to easily do this refactoring, I’d feel the need to find or create tools to help. I know there have been some talks and videos at PostgreSQL conferences which touch on the subject, but I’m not aware of any standard set of tools to help. Queries to find dependencies for example can get quite complex.
Are we in the minority in creating complex systems like this, are many people dealing with these questions separately, or is there a body of knowledge I’ve missed (embarrassing, but not unlikely!)
Further Work
As my understanding of this area and customer needs improves, we may add further refactoring features, similar to the automatic refactoring tools that coding IDEs (Integrated Development Environments) provide.
For example, we’ve had feedback from No-Code developers that being able to extract calculation columns from a view into a separate view would be a great time saver. Often a workflow involves something like
- create a new view, A
- join down to a ‘child’ table and add an aggregate calculation
- realise you want to add an aggregate of a second ‘child’ table
- clone the view, or create a new one from scratch, B, to recreate the first aggregate
- remove the aggregate and join from view A
- join A to B and reference the aggregate
- carry on with your plans from step 3
It seems like automating steps 4, 5 and 6 would be a great quick win to make developers’ lives easier. Expect to see something like that in the pipeline.
Credits
Thanks to Simon Williamson and his talk Big Opportunities in Small Data, and Claire Giordano for curating it so I found it. That talk made me think – yes, a lot of the data in our systems is ‘small’ – up to tens of millions of rows but down to a few thousand per table (down to one record per table in some cases). So I thought I’d write about what is interesting to me about it, hence this post.
Lastly, as I often do, I must give props to the PostgreSQL project itself. I made the decision to start using PostgreSQL for our major projects about twenty years ago and it’s the one major architectural decision that I get happier and happier about every day. We put so many demands on it and I love to see it humming along.
About Agilebase
www.agilebase.co.uk – the leading No Code CRM platform. As a Citizen Developer, create your own database applications. Powered with PostgreSQL.
See us at techSPARK’s Bath Digital Festival on the 12th July.

Leave a comment